INFRASTRUCTURE GROUP
Bricks to Bytes: Building a Digital Future


Unlocking 70 Years of Data
Kablamo built a multi-tenant data lake that unlocked over 70 years of documentation and petabytes of operational data for one of Australia's largest infrastructure groups, enabling new digital products and revenue streams from data that was previously locked in print and PDF.
“After almost 70 years developing, financing and managing infrastructure around the world, it was time to disrupt traditional business and build new data-driven revenue streams.”
Infrastructure Group, Digital Transformation
The Challenge
After almost 70 years developing, financing and managing residential and commercial infrastructure across Australia, Asia, Europe and the Americas, the client had accumulated an enormous volume of operational data but lacked the means to extract value from it. The data challenge was significant:
- Petabytes of data stored across various locations: designs, costings, security cameras, elevators, air conditioners, plus external data sources including air pollution, traffic, and weather
- 70+ years of documentation locked in print or PDF format
- Critical security, governance, and compliance requirements across the portfolio
- Very limited internal capabilities in rapid digital product development
The organisation's IT business unit wanted to demonstrate that printed and PDF documentation could be recovered into machine-readable format using ML. If the approach worked, it would open the door to more efficient use of current property assets and new digital products built on data that had been invisible for decades.
The Approach
Kablamo structured the engagement into two parallel streams: a Data Stream covering data lake design, build, and AI/ML model development, and a Business Development Stream covering digital product development and growth analysis.
The first phase focused on establishing the cloud foundations. The team set up AWS account structures, VPCs, landing zones, and IAM policies, then assessed and validated data sources for ingestion. An AWS Data Lake framework was established with an initial dataset covering construction sources, alongside CI/CD and data pipelines. Data governance and security postures were defined from the outset, with the target of delivering a searchable data lake within the first weeks.
The second phase extended the platform with completed Data Lake APIs, expanded data ingestion pipelines with cleaning and transformation, established data relationships across sources, extracted the first actionable insights, and built an initial digital product on top of the platform.
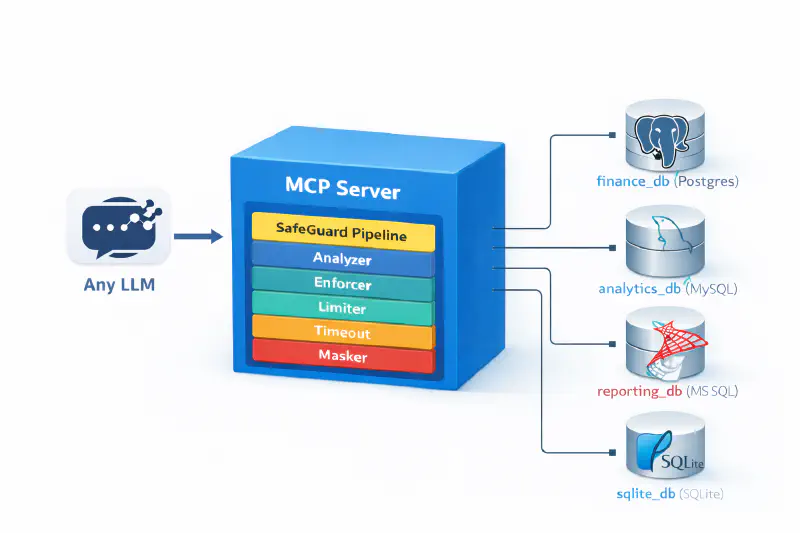
The data architecture followed event-driven, serverless workloads designed for automated scalability. Data flowed in one direction: raw to queryable to enriched. Multiple ingestion methods were supported including secure cross-account ingestion, bespoke APIs via API Gateway and Lambda, and Kinesis streams for real-time data. All queryable data was stored in Parquet format for efficient Athena queries.
The platform was built entirely on AWS serverless services. Glue handled data categorisation and ETL across real-time sources. Athena provided interactive queries on datasets of any size without provisioning infrastructure. Kinesis ingested real-time data streams from IoT sensors and operational systems, while Lambda and API Gateway served bespoke APIs. S3 and Glacier provided the storage tiers, from hot data lake to long-term archive.
AWS Textract was selected for the PDF extraction workstream, converting decades of printed and scanned documentation into machine-readable data. The team designed a processing pipeline that could handle the variety of document formats in the archive, from construction drawings and specifications to financial tables, and tuned extraction parameters iteratively to improve accuracy across different document types and layouts.
The Results
The intelligent data platform allows creation of a new data lake in minutes, compared to weeks with the previous approach. The platform supports multi-tenancy, enabling different business units and data science teams to work independently within isolated environments while sharing common infrastructure.
Textract results were strong for converting 70+ years of PDF documentation into machine-readable data. The team established a scalable extraction pattern applicable to over 100,000 files across the organisation, turning decades of locked information into queryable datasets. Complex documents containing tables, forms, and mixed layouts were handled through iterative refinement, producing structured output that could feed directly into the data lake's enrichment pipeline.
A custom user interface and data catalogue gave users a practical way to explore, search, and query the ingested data without needing direct access to the underlying AWS services.
Throughout the engagement, Kablamo worked alongside the company's internal digital teams to build the capabilities they would need to operate and extend the platform independently. This was not a handover at the end: engineers from both sides paired on architecture decisions, pipeline development, and Textract tuning from the first week.
Looking Forward
The infrastructure group can now build new revenue streams from data assets that were previously inaccessible. The serverless, event-driven architecture means the platform scales automatically as new data sources are connected and query volumes increase, without requiring additional infrastructure management.
Data science teams can access the queryable data layer to uncover insights and drive future product development. The Parquet-based storage and Athena query layer mean that analysts can run complex queries across petabytes of data without provisioning any compute infrastructure.
The multi-tenant architecture provides flexibility for integrations across the organisation and its global operations, supporting the long-term vision of building data-driven digital products on top of decades of accumulated operational knowledge. What was once paper in filing cabinets is now a queryable asset. The same platform that serves operational analytics today can support predictive maintenance, tenant insights, and new data products as the organisation's digital ambitions grow.